Rethinking Compute Substrates for 3D-Stacked Near-Memory LLMDecoding: Microarchitecture–Scheduling Co-Design
By Chenyang Ai 1, Yixing Zhang 2, Haoran Wu 3, Yudong Pan 4, Lechuan Zhao 2, Wenhui OU 5
1 University of Edinburgh, Edinburgh, United Kingdom
2 Peking University Beijing, China
3 University of Cambridge, Cambridge, United Kingdom
4 University of Chinese Academy of Sciences, Beijing, China
5 The Hong Kong University of Science and Technology, Hong Kong, China
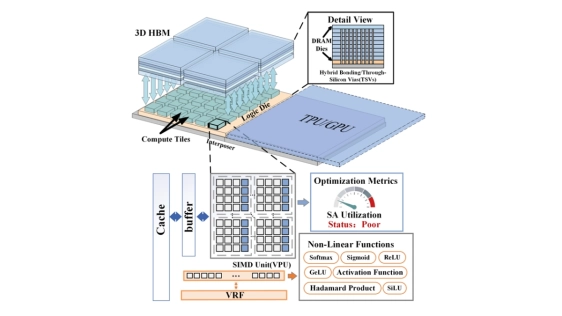
Abstract
Large language model (LLM) decoding is a major inference bottleneck because its low arithmetic intensity makes performance highly sensitive to memory bandwidth. 3D-stacked near-memory processing (NMP) provides substantially higher local memory band width than conventional off-chip interfaces, making it a promising substrate for decode acceleration. However, our analysis shows that this bandwidth advantage also shifts many decode operators on 3D-stacked NMP back into the compute-bound regime. Under the tight area budget of the logic die, the design of the compute substrate itself therefore becomes a first-order challenge.
Therefore, we rethink the compute microarchitecture of prior 3D-stacked NMP designs. First, we replace prior MAC tree-based compute units with a more area-efficient systolic array, and we further observe that decode operators exhibit substantial shape diversity, making reconfigurability in both systolic array shape and dataflow essential for sustaining high utilization. Building on this insight, we continue to exploit two key opportunities: the high local memory bandwidth reduces the need for large on-chip buffers, and the existing vector core, originally designed to handle auxiliary tensor computations, already provides much of the control logic and multi-ported buffering required for fine-grained flexibility for systolic array, allowing us to unify the two structures in a highly area-efficient manner. Based on these insights, we present the first compute microarchitecture tailored to 3D-stacked NMP LLM decoding, explicitly designed to satisfy the joint requirements of low area cost, high-bandwidth operation, and fine-grained reconfigurability.
To scale the design across multiple cores on one logic die, we further propose an operator-aware scheduling framework that combines spatial and spatio-temporal partitioning for LLM decode operators. Compared with Stratum, our design achieves an average 2.91× speedup and 2.40× higher energy efficiency across both dense and MoE models.
Keywords: 3D-Stacked NMP, LLM Decoding, Systolic Array Microarchitecture, Multi-Core Scheduling
To read the full article, click here
Related Chiplet
- Integrated voltage regulator (IVR) chiplet
- High-performance connectivity chiplets
- eFPGA Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
Related Technical Papers
- FoldedHexaTorus: An Inter-Chiplet Interconnect Topology for Chiplet-based Systems using Organic and Glass Substrates
- Modeling Chiplet-to-Chiplet (C2C) Communication for Chiplet-based Co-Design
- Corsair: An In-memory Computing Chiplet Architecture for Inference-time Compute Acceleration
- Mozart: A Chiplet Ecosystem-Accelerator Codesign Framework for Composable Bespoke Application Specific Integrated Circuits
Latest Technical Papers
- ThAME: 3D Memory-Enabled Heterogeneous Accelerator for LLM Mixture of Experts
- Thermo-mechanical reliability evaluation and comparative fatigue assessment of 2.5D chiplet packages with viscoelastic C4 underfill
- AI-Driven Thermal Mapping and Management in 3D Integrated Photonic Circuits
- CLIP-3D: Closed-Loop Evaluation of Performance and Physical Constraints for 3D ICs
- StreamDQ: Near-Memory Weight DeQuantization in Custom HBM for Scalable AI Inference Acceleration