Modeling Chiplet-to-Chiplet (C2C) Communication for Chiplet-based Co-Design
By Fabian Schatzle, Carlos Falquez, Nam Ho, Andre Zambanini, Johannes van den Boom and Estela Suarez
Forschungszentrum Julich GmbH
Abstract
Chiplet-based processor design, which combines small dies called chiplets to form a larger chip, enables scalable designs at economical costs. This trend has received high attention such that standards for chiplet design have rapidly established, including packaging, protocols, and Chiplet-to-Chiplet (C2C) interfaces. With numerous well-defined chiplet options available, hardware architects would leverage on the co-design process to make optimal decisions on design parameters.
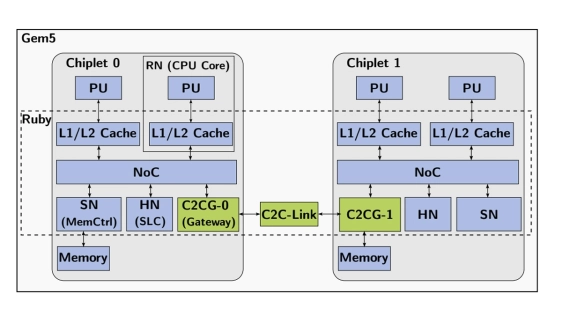
An important performance limitation in multi-chiplet designs come from the protocol translation in the C2C communication, needed to maintain cache coherency and avoid risk of deadlocks. When integrating multiple chiplets, deadlocks can happen from both protocol and routing, making deadlock-free designs important.
This paper tackles these challenges by introducing a Chiplet-to-Chiplet Gateway (C2CG) architecture, a C2C interface that bridges two chiplet protocols and ensures deadlock-free C2C communication. We also extend the Coherent Hub Interface (CHI) protocol to support cache coherent data sharing among cores across chiplets. The complete design is implemented in the gem5 simulator, constructing a modeling tool for chiplet-based co-design targeting next-generation High-performance Computing (HPC) processors. We demonstrate the benefit of the model through a design space exploration of three 64-core Armv8 HPC processor configurations: monolithic, two- and four-chiplet. The exploration, using representative HPC benchmarks, provides insights into C2C parameters and studies the impact of Non-Uniform Memory Access (NUMA) configuration, giving valuable co-design feedback for hardware architects.
Index Terms—High-Performance Computing, Chiplet, Cache coherency
To read the full article, click here
Related Chiplet
- Integrated voltage regulator (IVR) chiplet
- High-performance connectivity chiplets
- eFPGA Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
Related Technical Papers
- SHIFT: Dynamic Compute Relocation Framework for Communication-Aware Chiplet-Based Systems
- FoldedHexaTorus: An Inter-Chiplet Interconnect Topology for Chiplet-based Systems using Organic and Glass Substrates
- MCMComm: Hardware-Software Co-Optimization for End-to-End Communication in Multi-Chip-Modules
- Fault Modeling, Testing, and Repair for Chiplet Interconnects
Latest Technical Papers
- AI-Driven Thermal Mapping and Management in 3D Integrated Photonic Circuits
- CLIP-3D: Closed-Loop Evaluation of Performance and Physical Constraints for 3D ICs
- StreamDQ: Near-Memory Weight DeQuantization in Custom HBM for Scalable AI Inference Acceleration
- HCRMap: Pressure-Aware Hot-Expert Residency Mapping for 3.5D MoE Chiplet Inference
- Chiplet3D: Pin- and Thermal-Aware 3D Chiplet Floorplanning via Convolution-Embedded MILP