CCD-Level and Load-Aware Thread Orchestration for In-Memory Vector ANNS on Multi-Core CPUs
By Yuchen Huang †‡, Baiteng Ma †‡, Yiping Sun ‡, Yang Shi ‡, Xiao Chen ‡, Xiaocheng Zhong ‡, Zhiyong Wang ‡, Yao Hu ‡, Chuliang Weng †
† East China Normal University
‡ Xiaohongshu Inc (RedNote)
Abstract
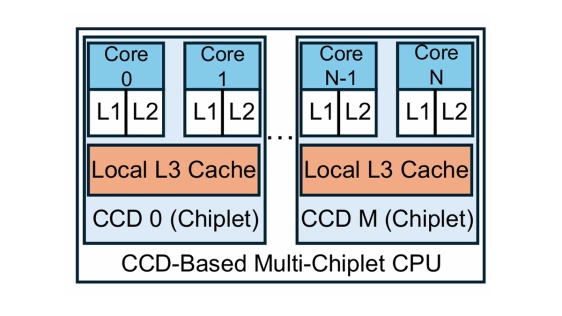
Vector approximate nearest neighbor search (ANNS) underpins search engines, recommendation systems, and advertising services. Recent advances in ANNS indexes make CPU a cost-effective choice for serving million-scale, in-memory vector search, yet per-core throughput remains constrained by memory access latency of vector reading and the compute intensity of distance evaluations in production deployments. With the growing scale of the business and advances in hardware, modern CCD-based multi-core CPUs have been widely deployed for high throughput in our services. However, we find that simply increas ing core counts does not yield optimal performance scaling.
To improve the efficiency of more cores from the CCD-based architecture, we analyze the distributions of real-world requests in our production environments. We observe high access locality in vector search in our online services and low cache utilization, resulting from overlooking the multi-chiplet nature of CCD based CPUs. Hence, we propose a workload- and hardware-aware thread orchestration framework at CCD-level that (i) provides a uniform interface for both inter-query parallel HNSW search and intra-query parallel IVF search, (ii) achieves cache-friendly and workload-adaptive mapping of task dispatching, and (iii) employs CCD-aware task stealing to address load imbalance.
Applied to real production workloads from search, recommendation, and advertising services of Xiaohongshu (RedNote), our approach delivers up to 3.7× higher throughput and 30–90% reductions in P50 and P999 latency. In detail, compared with the original framework, the cache-miss ratio decreases by 6–30%, and the total CPU stall is reduced by 20–80%.
Index Terms — Multi-core architecture, Vector search, Thread orchestration.
To read the full article, click here
Related Chiplet
- Integrated voltage regulator (IVR) chiplet
- High-performance connectivity chiplets
- eFPGA Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
Related Technical Papers
Latest Technical Papers
- APEX: an Adaptive Photonic-Electronic Chiplet Interconnection Architecture for DNN Inference
- Formal Foundations for Known Good Reliable Die Screening in Chiplet-Based AI Systems-on-Chip
- Optimization of Test-Access Architectures and Test Scheduling for 2.5D/3D Integration
- Learning to Place Chiplets: A Multi-Objective Reinforcement Learning Approach
- ThAME: 3D Memory-Enabled Heterogeneous Accelerator for LLM Mixture of Experts