Scope: A Scalable Merged Pipeline Framework for Multi-Chip-Module NN Accelerators
By Zongle Huang 1,3, Hongyang Jia 1, Kaiwei Zou 2, Yongpan Liu 1,3
1 Tsinghua University,
2 Capital Normal University,
3 Beijing National Research Center for Information Science and Technology
Abstract
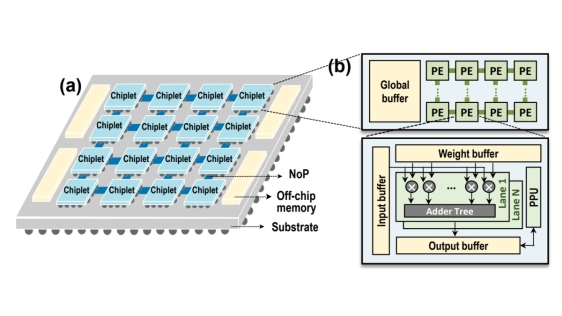
Neural network (NN) accelerators with multi-chip-module (MCM) architectures enable integration of massive computation capability; however, they face challenges of computing resource underutilization and off-chip communication overheads. Traditional parallelization schemes for NN inference on MCM architectures, such as intra-layer parallelism and inter-layer pipelining, show incompetency in breaking through both challenges, limiting the scalability of MCM architectures.
We observed that existing works typically deploy layers separately rather than considering them jointly. This underexploited dimension leads to compromises between system computation and communication, thus hindering optimal utilization, especially as hardware/software scale. To address this limitation, we propose Scope, a merged pipeline framework incorporating this overlooked multi-layer dimension, thereby achieving improved throughput and scalability by relaxing tradeoffs between computation, communication and memory costs. This new dimension, however, adds to the complexity of design space exploration (DSE). To tackle this, we develop a series of search algorithms that achieves exponential-to-linear complexity reduction, while identifying solutions that rank in the top 0.05% of performance. Experiments show that Scope achieves up to 1.73x throughput improvement while maintaining similar energy consumption for ResNet-152 inference compared to state-of-the-art approaches.
Index Terms — NN inference, MCM, chiplet, scheduling, DSE
To read the full article, click here
Related Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
- Near-Packaged Optics (NPO) Chiplet Solution
- High Performance Droplet
- Interconnect Chiplet
Related Technical Papers
- DeepStack: Scalable and Accurate Design Space Exploration for Distributed 3D-Stacked AI Accelerators
- AuthenTree: A Scalable MPC-Based Distributed Trust Architecture for Chiplet-based Heterogeneous Systems
- ATSim: A Fast and Accurate Simulation Framework for 2.5D/3D Chiplet Thermal Design Optimization
- Mozart: A Chiplet Ecosystem-Accelerator Codesign Framework for Composable Bespoke Application Specific Integrated Circuits
Latest Technical Papers
- Failure Analysis in Transition: An Industry Survey of Challenges, Priorities, and Standardization Needs in Advanced Packaging and Heterogeneous Integration
- 2.5D Root of Trust: Securing the Chiplet Ecosystem
- Plasma Etch Process Optimization for Photonic-Grade Diamond-on-Insulator Substrates and Thickness Evaluation using Colorimetry
- CUTh-Solver: GPU-Accelerated Sparse Matrix Solver for High-Resolution Thermal Simulation of 3D ICs
- Making Locality-aware GEMM Compatible with Page-Granularity Placement on Chiplet GPUs