AMMA: A Multi-Chiplet Memory-Centric Architecture for Low-Latency 1M Context Attention Serving
By Zhongkai Yu 1, Haotian Ye 1, Chenyang Zhou 2, Ohm Rishabh Venkatachalam 1, Zaifeng Pan 1, Zhengding Hu 1, Junsung Kim 3, Won Woo Ro 3, Po-An Tsai 4, Shuyi Pei 5, Yangwook Kang 5, Yufei Ding 1
1 University of California, San Diego, La Jolla, CA, USA
2 Columbia University, New York, NY, USA
3 Yonsei University, Seoul, Republic of Korea
4 NVIDIA, Santa Clara, CA, USA
5 Samsung Semiconductor, Inc., San Jose, CA, USA
Abstract
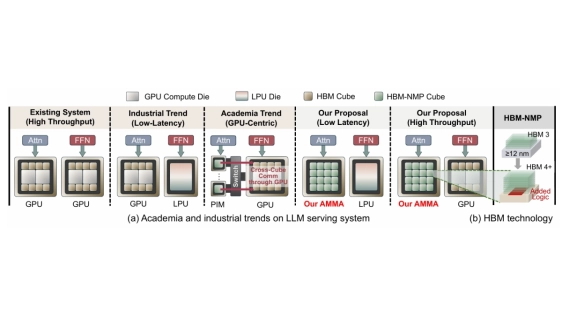
All current LLM serving systems place the GPU at the center, from production-level attention-FFN disaggregation to NVIDIA's Rubin GPU-LPU heterogeneous platform. Even academic PIM/PNM proposals still treat the GPU as the central hub for cross-device communication. Yet the GPU's compute-rich architecture is fundamentally mismatched with the memory-bound nature of decode-phase attention, inflating serving latency while wasting power and die area on idle compute units. The problem is compounded as reasoning and agentic workloads push context lengths toward one million tokens, making attention latency the primary user-facing bottleneck.
To address these inefficiencies, we present AMMA, a multi-chiplet, memory-centric architecture for low-latency long-context attention. AMMA replaces GPU compute dies with HBM-PNM cubes, roughly doubling the available memory bandwidth to better serve memory-bound attention workloads. To translate this bandwidth into proportional performance gains, we introduce (i) a logic-die microarchitecture that fully exploits per-cube internal bandwidth for decode attention under a minimal power and area budget, (ii) a two-level hybrid parallelism scheme, and (iii) a reordered collective flow that reduces intra-chip die-to-die communication overhead. We further conduct a design-space exploration over per-cube compute power and intra-chip D2D link bandwidth, providing actionable guidance for hardware designers. Evaluations show that AMMA achieves 15.5X lower attention latency and 6.9X lower energy consumption compared with the NVIDIA H100.
To read the full article, click here
Related Chiplet
- Integrated voltage regulator (IVR) chiplet
- High-performance connectivity chiplets
- eFPGA Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
Related Technical Papers
- 3DLS: A 3D Logic-Stacked Architecture for Disaggregated LLM Serving
- Lifecycle Cost-Effectiveness Modeling for Redundancy-Enhanced Multi-Chiplet Architectures
- Resister: A Resilient Interposer Architecture for Chiplet to Mitigate Timing Side-Channel Attacks
- AuthenTree: A Scalable MPC-Based Distributed Trust Architecture for Chiplet-based Heterogeneous Systems
Latest Technical Papers
- APEX: an Adaptive Photonic-Electronic Chiplet Interconnection Architecture for DNN Inference
- Formal Foundations for Known Good Reliable Die Screening in Chiplet-Based AI Systems-on-Chip
- Optimization of Test-Access Architectures and Test Scheduling for 2.5D/3D Integration
- Learning to Place Chiplets: A Multi-Objective Reinforcement Learning Approach
- ThAME: 3D Memory-Enabled Heterogeneous Accelerator for LLM Mixture of Experts