Technology solutions targeting the performance of gen-AI inference in resource constrained platforms
By Joyjit Kundu, Joshua Klein, Aakash Patel, Dwaipayan Biswas
Interuniversity Microelectronics Centre (IMEC), Belgium
Abstract
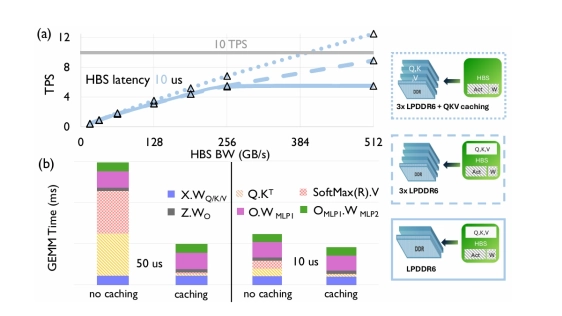
The rise of generative AI workloads, particularly language model inference, is intensifying on/off-chip memory pressure. Multimodal inputs such as video streams or images and downstream applications like Question Answering (QA) and analysis over large documents incur long context lengths, requiring caching of massive Key and Value states of the previous tokens. Even a low degree of concurrent inference serving on resource-constrained devices, like mobiles, can further add to memory capacity pressure and runtime memory management complexity. In this paper, we evaluate the performance implications of two emerging technology solutions to alleviate the memory pressure in terms of both capacity and bandwidth using a hierarchical roofline-based analytical performance model. For large models (e.g., 13B parameters) and context lengths, we investigate the performance implications of High Bandwidth Storage (HBS) and outline bandwidth/latency requirements to achieve an acceptable throughput for interactivity. For small models (e.g., 1B parameters), we evaluate the merit of a bonded global buffer memory chiplet and propose how to best utilize it.
To read the full article, click here
Related Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
- Near-Packaged Optics (NPO) Chiplet Solution
- High Performance Droplet
- Interconnect Chiplet
Related Technical Papers
- The Revolution of Chiplet Technology in Automotive Electronics and Its Impact on the Supply Chain
- Thermal Implications of Non-Uniform Power in BSPDN-Enabled 2.5D/3D Chiplet-based Systems-in-Package using Nanosheet Technology
- The Next Frontier in Semiconductor Innovation: Chiplets and the Rise of 3D-ICs
- Codesign of quantum error-correcting codes and modular chiplets in the presence of defects
Latest Technical Papers
- Failure Analysis in Transition: An Industry Survey of Challenges, Priorities, and Standardization Needs in Advanced Packaging and Heterogeneous Integration
- 2.5D Root of Trust: Securing the Chiplet Ecosystem
- Plasma Etch Process Optimization for Photonic-Grade Diamond-on-Insulator Substrates and Thickness Evaluation using Colorimetry
- CUTh-Solver: GPU-Accelerated Sparse Matrix Solver for High-Resolution Thermal Simulation of 3D ICs
- Making Locality-aware GEMM Compatible with Page-Granularity Placement on Chiplet GPUs