Scaling Routers with In-Package Optics and High-Bandwidth Memories
By Isaac Keslassy 1,2, Ilay Yavlovich 1, Jose Yallouz 1, Tzu-Chien Hsueh 3, Yeshaiahu Fainman 3, Bill Lin 3
1 Technion
2 UC Berkeley
3 UC San Diego
Abstract
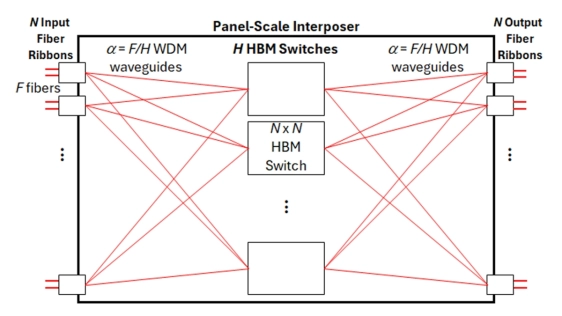
This paper aims to apply two major scaling transformations from the computing packaging industry to internet routers: the heterogeneous integration of high-bandwidth memories (HBMs) and chiplets, as well as in-package optics. We propose a novel internet router architecture that employs these technologies to achieve a petabit/sec router within a single integrated package. At the top-level, we introduce a novel split-parallel switch architecture that spatially divides (without processing) the incoming fibers and distributes them across smaller independent switches without intermediate OEO conversions or fine-tuned per-packet load-balancing. This passive spatial division enables scaling at the cost of a coarser traffic load balancing. Yet, through extensive evaluations of backbone network traffic, we demonstrate that differences with fine-tuned approaches are small. In addition, we propose a novel HBM-based shared-memory architecture for the implementation of the smaller independent switches, and we introduce a novel parallel frame interleaving algorithm that packs traffic into frames so that HBM banks are accessed at peak HBM data rates in a cyclical interleaving manner. We further discuss why these new technologies represent a paradigm shift in the design of future internet routers. Finally, we emphasize that power consumption may constitute the primary bottleneck to scaling.
To read the full article, click here
Related Chiplet
- eFPGA Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
- Near-Packaged Optics (NPO) Chiplet Solution
- High Performance Droplet
Related Technical Papers
- Intel Delivers Cutting-Edge Process Technologies to the Data Center with Intel 18A and Advanced Chiplet Packaging
- Understanding In-Package Optical I/O Versus Co-Packaged Optics
- Understanding In-Package Optical I/O Versus Co-Packaged Optics
- Occamy: A 432-Core 28.1 DP-GFLOP/s/W 83% FPU Utilization Dual-Chiplet, Dual-HBM2E RISC-V-based Accelerator for Stencil and Sparse Linear Algebra Computations with 8-to-64-bit Floating-Point Support in 12nm FinFET
Latest Technical Papers
- HCRMap: Pressure-Aware Hot-Expert Residency Mapping for 3.5D MoE Chiplet Inference
- Chiplet3D: Pin- and Thermal-Aware 3D Chiplet Floorplanning via Convolution-Embedded MILP
- The Signal-Integrity Control Strategy of a TSV Array for a Chiplet-Based System
- ThermoDSE: A Thermal-Aware and Comprehensive Design Space Exploration for Chiplet-Based DNN Accelerators
- GPU-Accelerated Effective Resistance Analysis for 3D IC Power Delivery Network