Fleet: Hierarchical Task-based Abstraction for Megakernels on Multi-Die GPUs
By Sangeeta Chowdhary, Ryan Swann, Sean Siddens, Muhammad Osama, Stephen Neuendorffer, Alexandru Dutu, Karthik Sangaiah, Sandeepa Bhuyan, Samuel Bayliss, Ganesh Dasika
AMD Research
Abstract
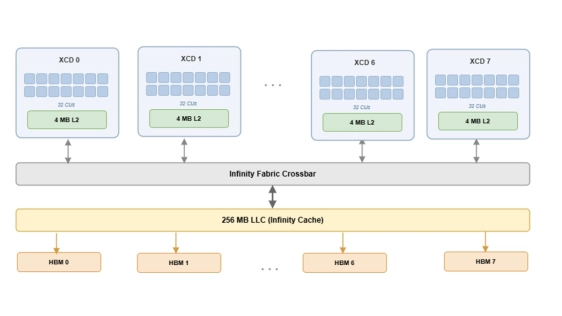
Modern GPUs adopt chiplet-based designs with multiple private cache hierarchies, but current programming models (CUDA/HIP) expose a flat execution hierarchy that cannot express chiplet-level locality or synchronization. This mismatch leads to redundant memory traffic and poor cache utilization in memory-bound workloads such as LLM inference.
We present Fleet, a multi-level task model that maps computation to memory scopes. Fleet introduces Chiplet-tasks, a new abstraction that binds work and data to a chiplet and enables coordination through its shared L2 cache. Wavefront-level, CU-level, and device-level tasks align with existing abstractions, while Chiplet-tasks expose a previously unaddressed level of the hierarchy. Fleet is implemented as a persistent kernel runtime with per-chiplet scheduling, allowing workers within a chiplet to cooperatively execute tasks with coordinated cache reuse. On AMD Instinct MI350 with Qwen3-8B, Fleet achieves 1.3-1.5x lower decode latency than vLLM at batch sizes 1-8 through persistent kernel execution and per-chiplet scheduling. At larger batch sizes, cooperative weight tiling increases L2 hit rate (from 12% to 54% at batch size 32 and from 39% to 61% at batch size 64), reducing HBM traffic by up to 37% and delivering 1.27-1.30x speedup over a chiplet-unaware megakernel baseline.
To read the full article, click here
Related Chiplet
- Integrated voltage regulator (IVR) chiplet
- High-performance connectivity chiplets
- eFPGA Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
Related Technical Papers
- Leveraging Chiplet-Locality for Efficient Memory Mapping in Multi-Chip Module GPUs
- Taming the Tail: NoI Topology Synthesis for Mixed DL Workloads on Chiplet-Based Accelerators
- CHIPSIM: A Co-Simulation Framework for Deep Learning on Chiplet-Based Systems
- Optimizing Attention on GPUs by Exploiting GPU Architectural NUMA Effects
Latest Technical Papers
- APEX: an Adaptive Photonic-Electronic Chiplet Interconnection Architecture for DNN Inference
- Formal Foundations for Known Good Reliable Die Screening in Chiplet-Based AI Systems-on-Chip
- Optimization of Test-Access Architectures and Test Scheduling for 2.5D/3D Integration
- Learning to Place Chiplets: A Multi-Objective Reinforcement Learning Approach
- ThAME: 3D Memory-Enabled Heterogeneous Accelerator for LLM Mixture of Experts