Expert Streaming: Accelerating Low-Batch MoE Inference via Multi-chiplet Architecture and Dynamic Expert Trajectory Scheduling
By Songchen Ma 1,2, Hongyi Li 2, Weihao Zhang 1,2, Yonghao Tan 1,2, Pingcheng Dong 1,2, Yu Liu 1, Lan Liu 3, Yuzhong Jiao 1, Xuejiao Liu 1, Luhong Liang 1, Kwang-Ting Cheng 1,2
1 AI Chip Center for Emerging Smart Systems, Hong Kong SAR, China
2 The Hong Kong University of Science and Technology, Hong Kong SAR, China
3 Shanghai UniVista Industrial Software Group Co., Ltd., Shanghai, China
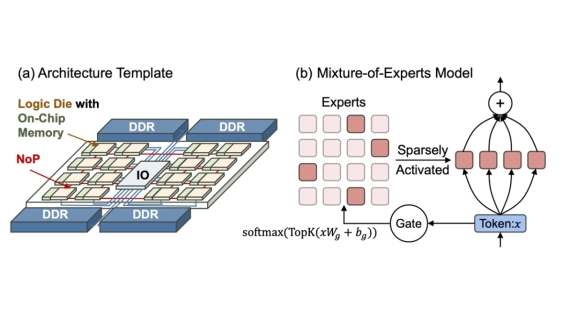
Abstract
Mixture-of-Experts is a promising approach for edge AI with low-batch inference. Yet, on-device deployments often face limited on-chip memory and severe workload imbalance; the prevalent use of offloading further incurs off-chip memory access bottlenecks. Moreover, MoE sparsity and dynamic gating shift distributed strategies toward much finer granularity and introduce runtime scheduling considerations. Recently, high die-to-die bandwidth chiplet interconnects have created new opportunities for multi-chiplet systems to address workload imbalance and offloading bottlenecks with fine-grained scheduling. In this paper, we propose Fully Sharded Expert Data Parallelism, a parallelization paradigm specifically architected for low-batch MoE inference on multi-chiplet accelerators. FSE-DP attains adaptive computation-communication overlap and balanced load by orchestrating fine-grained, complementary expert streams along dynamic trajectories across high-bandwidth D2D links. The attendant dataflow complexity is tamed by a minimal, hardware-amenable set of virtualization rules and a lightweight scheduling algorithm. Our approach achieves 1.22 to 2.00 times speedup over state-of-the-art baselines and saves up to 78.8 percent on-chip memory.
To read the full article, click here
Related Chiplet
- Integrated voltage regulator (IVR) chiplet
- High-performance connectivity chiplets
- eFPGA Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
Related Technical Papers
- MFIT : Multi-FIdelity Thermal Modeling for 2.5D and 3D Multi-Chiplet Architectures
- THERMOS: Thermally-Aware Multi-Objective Scheduling of AI Workloads on Heterogeneous Multi-Chiplet PIM Architectures
- Towards Future Microsystems: Dynamic Validation and Simulation in Chiplet Architectures
- Mozart: Modularized and Efficient MoE Training on 3.5D Wafer-Scale Chiplet Architectures
Latest Technical Papers
- APEX: an Adaptive Photonic-Electronic Chiplet Interconnection Architecture for DNN Inference
- Formal Foundations for Known Good Reliable Die Screening in Chiplet-Based AI Systems-on-Chip
- Optimization of Test-Access Architectures and Test Scheduling for 2.5D/3D Integration
- Learning to Place Chiplets: A Multi-Objective Reinforcement Learning Approach
- ThAME: 3D Memory-Enabled Heterogeneous Accelerator for LLM Mixture of Experts