DUET: Disaggregated Hybrid Mamba-Transformer LLMs with Prefill and Decode-Specific Packages
By Alish Kanani 1, Sangwan Lee 2, Han Lyu 1, Jiahao Lin 1, Jaehyun Park 2, Umit Y. Ogras 1
1 University of Wisconsin–Madison
2 University of Ulsan
Abstract
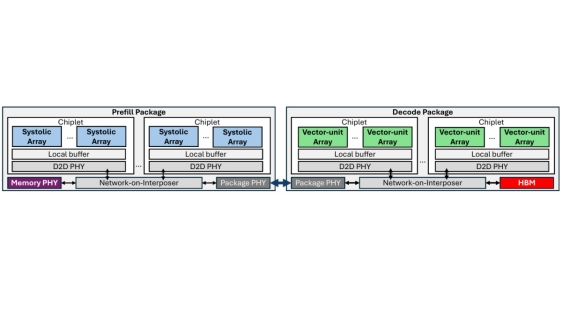
Large language models operate in distinct compute-bound prefill followed by memory bandwidth-bound decode phases. Hybrid Mamba-Transformer models inherit this asymmetry while adding state space model (SSM) recurrences and element-wise operations that map poorly to matmul-centric accelerators. This mismatch causes performance bottlenecks, showing that a homogeneous architecture cannot satisfy all requirements. We introduce DUET, a disaggregated accelerator that assigns prefill and decode phases to specialized packages. The Prefill package utilizes systolic array chiplets with off-package memory for efficient large matrix multiplications and long-sequence SSMs. The Decode package utilizes vector-unit arrays with high-bandwidth in-package memory to accelerate token-by-token SSM and vector-matrix multiplications. Both architectures are runtime-configurable to support hybrid models with mixed Mamba and attention layers. Evaluations on Nemotron-H-56B, Zamba2-7B, and Llama3-8B across four workloads show that DUET achieves 4x faster time to first token, 1.4x higher throughput, and 1.5x lower time between tokens over the B200 GPU.
To read the full article, click here
Related Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
- Near-Packaged Optics (NPO) Chiplet Solution
- High Performance Droplet
- Interconnect Chiplet
Related Technical Papers
- Thermo-mechanical co-design of 2.5D flip-chip packages with silicon and glass interposers via finite element analysis and machine learning
- Intel Delivers Cutting-Edge Process Technologies to the Data Center with Intel 18A and Advanced Chiplet Packaging
- Occamy: A 432-Core 28.1 DP-GFLOP/s/W 83% FPU Utilization Dual-Chiplet, Dual-HBM2E RISC-V-based Accelerator for Stencil and Sparse Linear Algebra Computations with 8-to-64-bit Floating-Point Support in 12nm FinFET
- Hecaton: Training and Finetuning Large Language Models with Scalable Chiplet Systems
Latest Technical Papers
- Failure Analysis in Transition: An Industry Survey of Challenges, Priorities, and Standardization Needs in Advanced Packaging and Heterogeneous Integration
- 2.5D Root of Trust: Securing the Chiplet Ecosystem
- Plasma Etch Process Optimization for Photonic-Grade Diamond-on-Insulator Substrates and Thickness Evaluation using Colorimetry
- CUTh-Solver: GPU-Accelerated Sparse Matrix Solver for High-Resolution Thermal Simulation of 3D ICs
- Making Locality-aware GEMM Compatible with Page-Granularity Placement on Chiplet GPUs