Advanced Chiplet Placement and Routing Optimization considering Signal Integrity
By Haeyeon Kim, Junghyun Lee, Seonguk Choi, Federico Berto, Taein Shin, Joonsang Park, Jihun Kim, Jiwon Yoon, Byeongmok Kim, Youngwoo Kim, and Joungho Kim
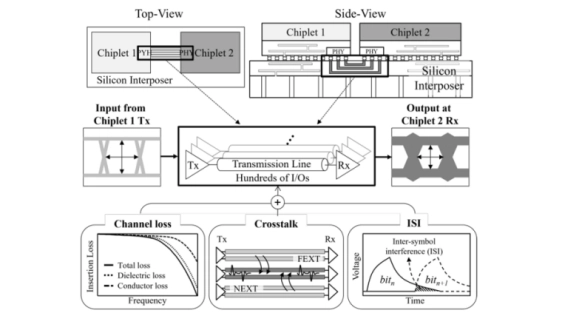
Abstract:
This article addresses the critical challenges of chiplet placement and routing optimization in the era of advanced packaging and heterogeneous integration. We present a novel approach that formulates the problem as a signal integrity-aware hierarchical Markov decision process (MDP), leveraging the place-to-route (P2R) algorithm. Our method uniquely incorporates the universal chiplet interconnect express (UCIe) eye mask specifications to ensure compliance with datarate-dependent signal integrity requirements. Tested on 10 benchmark problems, P2R achieved superior results with an average eye-diagram aperture of 0.869 unit interval (UI) in a single iteration, outperforming random search and deep reinforcement learning by 44.8%. By addressing the combinatorial complexity and hard constraints inherent in chiplet-based designs, this approach enables optimization while ensuring compliance with industry standards. Our work represents a significant advancement in optimizing heterogeneous integrated systems, addressing challenges that conventional placement and routing methods cannot adequately solve.
To read the full article, click here
Related Chiplet
- Integrated voltage regulator (IVR) chiplet
- High-performance connectivity chiplets
- eFPGA Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
Related Technical Papers
- FAPlace: Joint Optimization of Chiplet Placement and Interposer Footprint for 2.5D Systems
- Tiny Chiplets Enabled by Packaging Scaling: Opportunities in ESD Protection and Signal Integrity
- Intel Delivers Cutting-Edge Process Technologies to the Data Center with Intel 18A and Advanced Chiplet Packaging
- Achieving Better Chiplet Design Signal Integrity with UCIe™
Latest Technical Papers
- APEX: an Adaptive Photonic-Electronic Chiplet Interconnection Architecture for DNN Inference
- Formal Foundations for Known Good Reliable Die Screening in Chiplet-Based AI Systems-on-Chip
- Optimization of Test-Access Architectures and Test Scheduling for 2.5D/3D Integration
- Learning to Place Chiplets: A Multi-Objective Reinforcement Learning Approach
- ThAME: 3D Memory-Enabled Heterogeneous Accelerator for LLM Mixture of Experts