A3D-MoE: Acceleration of Large Language Models with Mixture of Experts via 3D Heterogeneous Integration
By Wei-Hsing Huang, Janak Sharda, Cheng-Jhih Shih, Yuyao Kong, Faaiq Waqar, Pin-Jun Chen, Yingyan (Celine) Lin and Shimeng Yu - Georgia Institute of Technology
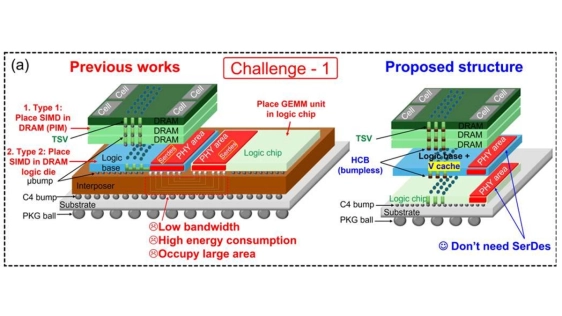
Abstract
Conventional large language models (LLMs) are equipped with dozens of GB to TB of model parameters, making inference highly energy-intensive and costly as all the weights need to be loaded to onboard processing elements during computation. Recently, the Mixture-of-Experts (MoE) architecture has emerged as an efficient alternative, promising efficient inference with less activated weights per token. Nevertheless, fine-grained MoE-based LLMs face several challenges: 1) Variable workloads during runtime create arbitrary GEMV-GEMM ratios that reduce hardware utilization, 2) Traditional MoE-based scheduling for LLM serving cannot fuse attention operations with MoE operations, leading to increased latency and decreased hardware utilization, and 3) Despite being more efficient than conventional LLMs, loading experts from DRAM still consumes significant energy and requires substantial DRAM bandwidth. Addressing these challenges, we propose: 1) A3D-MoE, a 3D Heterogeneous Integration system that employs state-of-the-art vertical integration technology to significantly enhance memory bandwidth while reducing Network-on-Chip (NoC) overhead and energy consumption. 2) A 3D-Adaptive GEMV-GEMM-ratio systolic array with V-Cache efficient data reuse and a novel unified 3D dataflow to solve the problem of reduced hardware utilization caused by arbitrary GEMV-GEMM ratios from different workloads, 3) A Hardware resource-aware operation fusion scheduler that fuses attention operations with MoE operations to enhance hardware performance, and 4) MoE Score-Aware HBM access reduction with even-odd expert placement that reduces DRAM access and bandwidth requirements. Our evaluation results indicate that A3D-MoE delivers significant performance enhancements, reducing latency by a factor of 1.8x to 2x and energy consumption by 2x to 4x, while improving throughput by 1.44x to 1.8x compared to the state-of-the-art.
Keywords— Fine-grained MoE structures acceleration, 3D Heterogeneous Integration, Software-Hardware Co-Design
To read the full article, click here
Related Chiplet
- Integrated voltage regulator (IVR) chiplet
- High-performance connectivity chiplets
- eFPGA Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
Related Technical Papers
- ThAME: 3D Memory-Enabled Heterogeneous Accelerator for LLM Mixture of Experts
- Co-Optimization of Power Delivery Network Design for 3-D Heterogeneous Integration of RRAM-Based Compute In-Memory Accelerators
- Workflows for tackling heterogeneous integration of chiplets for 2.5D/3D semiconductor packaging
- Five Workflows for Tackling Heterogeneous Integration of Chiplets for 2.5D/3D
Latest Technical Papers
- APEX: an Adaptive Photonic-Electronic Chiplet Interconnection Architecture for DNN Inference
- Formal Foundations for Known Good Reliable Die Screening in Chiplet-Based AI Systems-on-Chip
- Optimization of Test-Access Architectures and Test Scheduling for 2.5D/3D Integration
- Learning to Place Chiplets: A Multi-Objective Reinforcement Learning Approach
- ThAME: 3D Memory-Enabled Heterogeneous Accelerator for LLM Mixture of Experts