On-Package Memory with Universal Chiplet Interconnect Express (UCIe): A Low Power, High Bandwidth, Low Latency and Low Cost Approach
By Debendra Das Sharma 1, Swadesh Choudhary 1, Peter Onufryk 1, and Rob Pelt 2
1 Intel Corporation
2 AMD Corporation
Abstract
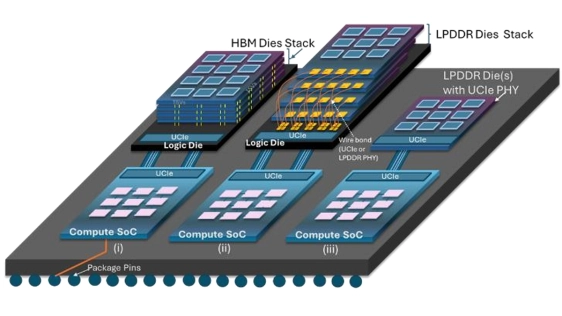
Emerging computing applications such as Artificial Intelligence (AI) are facing a memory wall with existing on-package memory solutions that are unable to meet the power-efficient bandwidth demands. We propose to enhance UCIe with memory semantics to deliver power-efficient bandwidth and cost-effective on-package memory solutions applicable across the entire computing continuum. We propose approaches by reusing existing LPDDR6 and HBM memory through a logic die that connects to the SoC using UCIe. We also propose an approach where the DRAM die natively supports UCIe instead of the LPDDR6 bus interface. Our approaches result in significantly higher bandwidth density (up to 10x), lower latency (up to 3x), lower power (up to 3x), and lower cost compared to existing HBM4 and LPDDR on-package memory solutions.
To read the full article, click here
Related Chiplet
- eFPGA Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
- Near-Packaged Optics (NPO) Chiplet Solution
- High Performance Droplet
Related Technical Papers
- Universal Chiplet Interconnect Express: An Open Industry Standard for Memory and Storage Applications
- High-performance, power-efficient three-dimensional system-in-package designs with universal chiplet interconnect express
- Achieving Better Chiplet Design Signal Integrity with UCIe™
- ChipLight: Cross-Layer Optimization of Chiplet Design with Optical Interconnects for LLM Training
Latest Technical Papers
- HCRMap: Pressure-Aware Hot-Expert Residency Mapping for 3.5D MoE Chiplet Inference
- Chiplet3D: Pin- and Thermal-Aware 3D Chiplet Floorplanning via Convolution-Embedded MILP
- The Signal-Integrity Control Strategy of a TSV Array for a Chiplet-Based System
- ThermoDSE: A Thermal-Aware and Comprehensive Design Space Exploration for Chiplet-Based DNN Accelerators
- GPU-Accelerated Effective Resistance Analysis for 3D IC Power Delivery Network