SHIFT: Dynamic Compute Relocation Framework for Communication-Aware Chiplet-Based Systems
By Arvin Delavari 1, Leonid Popryho 2, Inna Partin-Vaisband 2, Boris Vaisband 1
1 University of California, Irvine, USA
2 University of Illinois Chicago, USA
Abstract
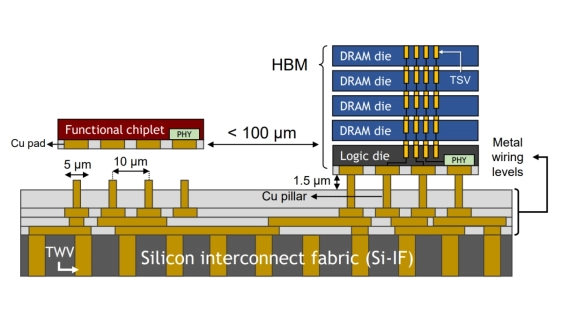
The increasing communication complexity of large-scale heterogeneous systems has motivated runtime methodologies for communication-aware workload placement and routing optimization. These communication limitations are addressed in this paper by proposing SHIFT, a novel topology-agnostic approach that transfers compute node context and data to a more suitably positioned node, rather than only shifting data as in conventional networks-on-chip. The proposed strategy is evaluated on a chiplet-based architecture utilizing a fine-pitch integration platform featuring multiple bandwidth-domains for heterogeneous workloads. The proposed architecture employs multi-layered routing between functional or memory chiplets and utility chiplets, which serve as intelligent nodes for routing and compute relocation. Adaptive scheduling and routing utilize a modified shortest-path algorithm for large-scale systems, complemented by a lightweight ML-assisted policy that infers traffic conditions to improve adaptivity. To establish a performance baseline, the initial assessment uses random instruction vectors and data patterns to evaluate the fundamental capabilities of SHIFT. Simulation results exhibit successful relocations over total trials ranging from 75.2% to 97.9% across configurations, with average latency improvements of 16.4%-62.5% and a maximum of 76.8%. In addition, throughput is improved by up to 12.5x, power dissipation per unit area is reduced by ~8%, energy-per-bit is reduced by up to 58.3%, and performance is improved by 18%. To evaluate efficiency under high logic and data density, the framework was tested on standard LLM workloads. Results exhibit average improvements of 4.9x, 5.9x, and 1.8x in runtime, throughput, and energy-efficiency, respectively, surpassing state-of-the-art wafer-scale LLM services and demonstrating compatibility with large-scale platforms and applications.
To read the full article, click here
Related Chiplet
- Integrated voltage regulator (IVR) chiplet
- High-performance connectivity chiplets
- eFPGA Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
Related Technical Papers
- CHIPSIM: A Co-Simulation Framework for Deep Learning on Chiplet-Based Systems
- Business Analysis of Chiplet-Based Systems and Technology
- AuthenTree: A Scalable MPC-Based Distributed Trust Architecture for Chiplet-based Heterogeneous Systems
- CarbonPATH: Carbon-aware pathfinding and architecture optimization for chiplet-based AI systems
Latest Technical Papers
- APEX: an Adaptive Photonic-Electronic Chiplet Interconnection Architecture for DNN Inference
- Formal Foundations for Known Good Reliable Die Screening in Chiplet-Based AI Systems-on-Chip
- Optimization of Test-Access Architectures and Test Scheduling for 2.5D/3D Integration
- Learning to Place Chiplets: A Multi-Objective Reinforcement Learning Approach
- ThAME: 3D Memory-Enabled Heterogeneous Accelerator for LLM Mixture of Experts