HexaMesh: Scaling to Hundreds of Chiplets with an Optimized Chiplet Arrangement
By Patrick Iff ∗, Maciej Besta ∗, Matheus Cavalcante †, Tim Fischer †, Luca Benini †‡ and Torsten Hoefler ∗
∗ Department of Computer Science, ETH Zurich, Zurich, Switzerland
† Department of Information Technology and Electrical Engineering, ETH Zurich, Zurich, Switzerland
‡ Dept. of Electrical, Electronic and Information Engineering, University of Bologna, Italy
Abstract
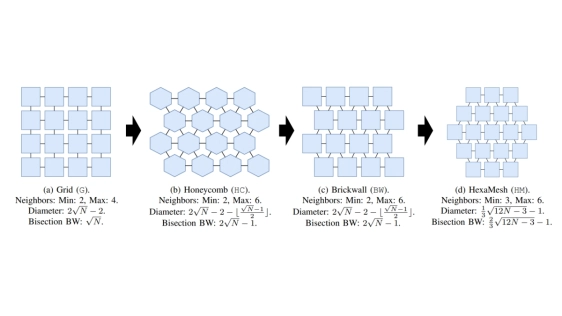
2.5D integration is an important technique to tackle the growing cost of manufacturing chips in advanced technology nodes. This poses the challenge of providing high-performance inter-chiplet interconnects (ICIs). As the number of chiplets grows to tens or hundreds, it becomes infeasible to hand-optimize their arrangement in a way that maximizes the ICI performance. In this paper, we propose HexaMesh, an arrangement of chiplets that outperforms a grid arrangement both in theory (network diameter reduced by 42%; bisection bandwidth improved by 130%) and in practice (latency reduced by 19%; throughput improved by 34%). HexaMesh enables large-scale chiplet designs with high-performance ICIs.
To read the full article, click here
Related Chiplet
- Integrated voltage regulator (IVR) chiplet
- High-performance connectivity chiplets
- eFPGA Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
Related Technical Papers
- Leveraging Modularity of Chiplets to Form a 4×4 Automotive FMCW-Radar in an eWLB-Package
- Intel Delivers Cutting-Edge Process Technologies to the Data Center with Intel 18A and Advanced Chiplet Packaging
- Thermo-mechanical reliability evaluation and comparative fatigue assessment of 2.5D chiplet packages with viscoelastic C4 underfill
- PICNIC: Silicon Photonic Interconnected Chiplets with Computational Network and In-memory Computing for LLM Inference Acceleration
Latest Technical Papers
- APEX: an Adaptive Photonic-Electronic Chiplet Interconnection Architecture for DNN Inference
- Formal Foundations for Known Good Reliable Die Screening in Chiplet-Based AI Systems-on-Chip
- Optimization of Test-Access Architectures and Test Scheduling for 2.5D/3D Integration
- Learning to Place Chiplets: A Multi-Objective Reinforcement Learning Approach
- ThAME: 3D Memory-Enabled Heterogeneous Accelerator for LLM Mixture of Experts