Making Locality-aware GEMM Compatible with Page-Granularity Placement on Chiplet GPUs
By Euijun Chung, Jae Hyung Ju, Hyesoon Kim
Georgia Institute of Technology
Abstract
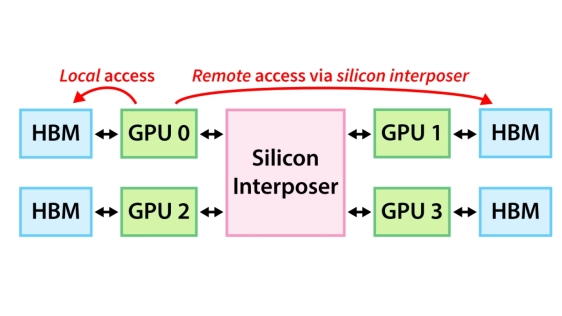
Multi-chiplet GPUs scale compute throughput and high-bandwidth memory (HBM) capacity, but their non-uniform memory system makes locality between chiplets and their data critical to the GPU's performance and energy efficiency. Locality-aware scheduling and data placement identify which data should reside near each chiplet. However, in general matrix multiplication (GEMM), locality-aware data placement often becomes incompatible with a fixed page-granularity data interleaving, since the optimal granularity for mapping data across chiplets varies widely across workloads. We propose Chiplet-Contiguous Layout, a global memory layout that stores chiplet-local data contiguously. Chiplet-Contiguous Layout enables locality-aware placement compatible with page-granularity placement across diverse large language model (LLM) GEMM shapes, without changes to the operating system or hardware. On representative LLM inference and training GEMMs from Qwen 3 30B and Llama 3.1 70B, Chiplet-Contiguous Layout on average reduces remote HBM traffic by 24.7x on Qwen and 19.2x on Llama over 4KB interleaving, and by 4.1x and 2.1x over coarse locality-aware placement.
Index Terms — Chiplet GPU, GEMM, data placement, memory layout, page-granularity placement.
To read the full article, click here
Related Chiplet
- eFPGA Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
- Near-Packaged Optics (NPO) Chiplet Solution
- High Performance Droplet
Related Technical Papers
- On-Package Memory with Universal Chiplet Interconnect Express (UCIe): A Low Power, High Bandwidth, Low Latency and Low Cost Approach
- High-performance, power-efficient three-dimensional system-in-package designs with universal chiplet interconnect express
- Intel Delivers Cutting-Edge Process Technologies to the Data Center with Intel 18A and Advanced Chiplet Packaging
- The Revolution of Chiplet Technology in Automotive Electronics and Its Impact on the Supply Chain
Latest Technical Papers
- HCRMap: Pressure-Aware Hot-Expert Residency Mapping for 3.5D MoE Chiplet Inference
- Chiplet3D: Pin- and Thermal-Aware 3D Chiplet Floorplanning via Convolution-Embedded MILP
- The Signal-Integrity Control Strategy of a TSV Array for a Chiplet-Based System
- ThermoDSE: A Thermal-Aware and Comprehensive Design Space Exploration for Chiplet-Based DNN Accelerators
- GPU-Accelerated Effective Resistance Analysis for 3D IC Power Delivery Network