Neoverse CSS N3: Fastest Path to Market Leading Power Efficiency

Disrupting Legacy Infrastructure
From Cloud to Edge, Arm Neoverse is disrupting legacy infrastructure silicon by providing unparalleled performance, efficiency, design flexibility, and TCO benefits.
We are seeing cloud and hyperscale service operators push to more computing density. With 128+ core CPU designs hitting the market (Microsoft Cobalt, Alibaba Yitian 710, AmpereOne) offering tremendous performance in a single package, and next generation targets aiming well above 128 cores.
Along with CPU performance, the need for specialized computing is growing continuously in the form of AI, networking and crypto accelerators. There is a clear need to bring those accelerators in package for performance and efficiency while allowing designs to be modular, in order to mix and match accelerators with different general purpose compute engines.
Neoverse CSS N3, a new Arm Neoverse CSS product based on the Neoverse N3 CPU
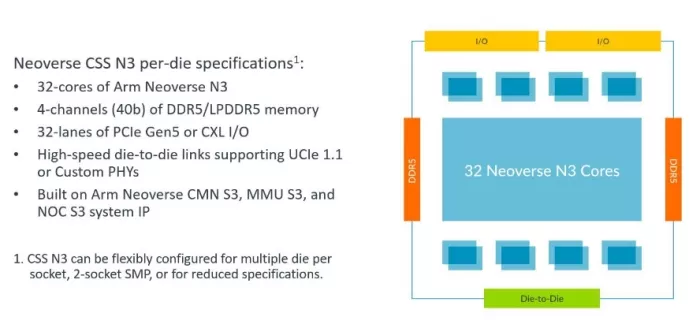
Figure 1. Neoverse CSS N3 overview
As a reminder, Neoverse Compute Subsystems (CSS) allow speed-of-light development of leading edge SoCs on latest process nodes. Partners have saved 80 engineer years in time and opportunity cost by going with pre-configured, pre-validated CSS for their design, enabling them to focus on their secret sauce value add to the system.
Neoverse CSS N3 is the follow on to the market proven Neoverse CSS N2, delivering improved performance and efficiency with new architectural features for leading perf/socket and perf/TCO in the datacenter market. Neoverse CSS N3 also brings unparalleled efficiency for edge and networking applications. CSS N3 is built on top of Neoverse S3 system IP which includes our coherent mesh network CMN S3, system memory management unit MMU S3, interrupt controller NOC S3. CSS N3 also includes system management and local control processors, with CPU and System IP co-design and co-development for optimized PPA and system-level feature enablement.
Neoverse CSS N3 supports 32 Neoverse N3 cores for maximum performance in a power envelope as low as 40W. It is highly configurable to cover Telco, DPU, Networking and cloud with scalability from 32-cores down to 8-cores.
On top of performance and efficiency improvements, Neoverse CSS N3 enables chiplet-based designs. With support for the UCIe die-to-die connection standard, together with Arm’s new AMBA CHI C2C protocol, CSS N3 is a foundation for building heterogenous, accelerated compute. We envision Arm Neoverse CSS N3 thriving in today’s specialized computing world where a CSS N3-based chiplet can be connected to an IO coherent accelerator over AMBA CHI C2C to bring accelerators on package for improved performance and efficiency. This can replace legacy solutions where accelerators are connected off-die through PCIe, leading to higher latency, more software complexity, and higher power consumption.
Neoverse N3 CPU: Class-Leading Efficiency
Performance efficiency, measured as performance-per-watt, is one of the most important metrics in CPU evaluation. 5G/6G wireless infrastructure demands more performance from modern computing solutions. And power budgets remain fixed. The new era of Data Processing Units (DPU) requires more capable CPU to run full-blown operating systems, virtual machines, containers, and other package processing functions within the limitation of PCIe device specifications. Hyperscalers are deploying denser CPUs with higher core counts while staying within the cooling capability of the rack. Power efficiency is a major design decision in almost all market segments. Neoverse N3 is designed with power efficiency as it's driving force.
Neoverse N3 CPUs carry forward the efficiency DNA that has been proven in the Neoverse N2. Arm's CPU design team worked tirelessly to enhance the branch predictor, prefetchers, and optimize the microarchitecture for efficiency. They improved power management and added finer-grained per-core DVFS to help extract even more performance efficiency. These changes result in a more than 20% efficiency improvement over the previous generation.
Neoverse N3 can support a wide range of SoC design points: from 16-cores networking designs through 32-core Telco RAN or Cloud DPU designs, to 192-core hyperscale and cloud CPUs. With a range of voltage and frequency choices, Neoverse N3 can deliver from 20% to almost 50% per-core performance-efficiency compared to Neoverse N2.
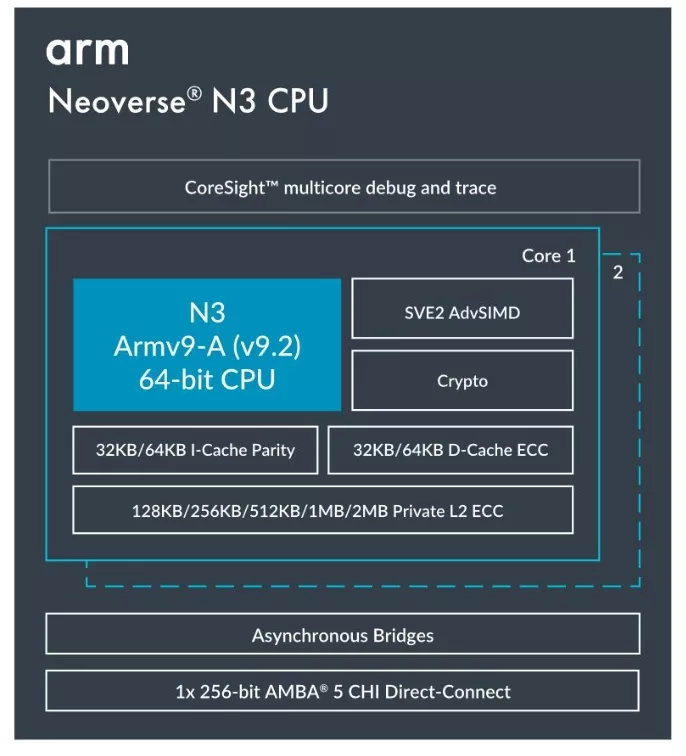
Figure 2. Arm Neoverse N3 CPU
Extending Best-in-class Efficiency Leadership
Neoverse N3 delivers performance improvements of approximately 3x on Machine Learning and data analytics workloads, 1.3x on SQL database, 1.2x on selected compression applications, and 1.1x on integer performance over Neoverse N2 – in approximately the same area and power profile as Neoverse N2 in the same technology node.
Flexible cache configurations
Neoverse N3 offers a wide range of cache configurations catering to different compute scenarios. Many scale-out cloud data analytics and database applications benefit from larger cache closer to the core, so we are introducing the 2MB L2 cache option for this segment. The 1MB L2 cache option offers a good performance and area tradeoff for general-purpose compute in variety of tasks ranging from 5G/6G wireless infrastructure, enterprise networking, DPU and SmartNIC, to hyperscale server; while the minimal 32KB L1 and 128KB option is suitable for workloads that are not cache sensitive, yet still demanding respected computing power in a small footprint.
Summary
The Neoverse N-series product line continues to deliver class-leading performance-per-watt with the Neoverse N3 CPU. With the new CSS N3, Arm combines the performance and efficiency of the Neoverse N3 with Neoverse S3 system IP and provides one of the most customizable compute subsystem in the industry offering 20% to almost 50% perf-per-watt improvements over the previous CSS generation. CSS N3 is a platform for cloud to edge designs that will allow our partners to create products incorporating Arm powerful processors with specialized components - whether they are crypto, networking or AI accelerators, or all of them – and differentiate themselves from the pack.
We anticipate exciting and innovative silicon designs based on Neoverse N3 and CSS N3 from our partners towards the end of 2024 and beyond.
Related Chiplet
- eFPGA Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
- Near-Packaged Optics (NPO) Chiplet Solution
- High Performance Droplet
Related Blogs
- Neoverse S3 System IP: A Foundation for Confidential Compute and Multi-chiplet Infrastructure SoCs
- Arm Zena CSS – Accelerating Chiplet-Based SoC Design for AI-Defined Vehicles
- Why Chiplets and why now?
- Arm Ecosystem Collaborates on Standards to Enable a Thriving Chiplet Market