PICNIC: Silicon Photonic Interconnected Chiplets with Computational Network and In-memory Computing for LLM Inference Acceleration
By Yue Jiet Chong, Yimin Wang, Zhen Wu and Xuanyao Fong
National University of Singapore, Singapore
Abstract
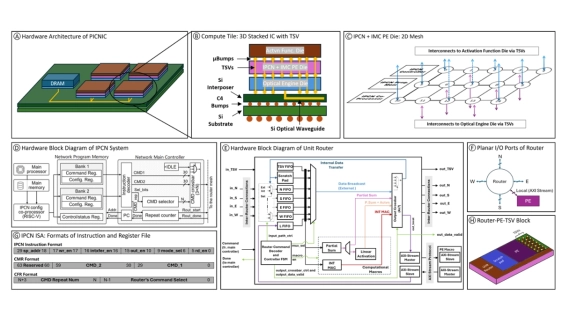
This paper presents a 3D-stacked chiplets based large language model (LLM) inference accelerator, consisting of non-volatile in-memory-computing processing elements (PEs) and Inter-PE Computational Network (IPCN), interconnected via silicon photonic to effectively address the communication bottlenecks. A LLM mapping scheme was developed to optimize hardware scheduling and workload mapping. Simulation results show it achieves 3.95× speedup and 30× efficiency improvement over the Nvidia A100 before chiplet clustering and power gating scheme (CCPG). Additionally, the system achieves further scalability and efficiency improvement with the implementation of CCPG to accommodate larger models, attaining 57× efficiency improvement over Nvidia H100 at similar throughput.
Index Terms: LLM Inference, Hardware Accelerator, HW-SW Co-design
To read the full article, click here
Related Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
- Near-Packaged Optics (NPO) Chiplet Solution
- High Performance Droplet
- Interconnect Chiplet
Related Technical Papers
- ChipAI: A scalable chiplet-based accelerator for efficient DNN inference using silicon photonics
- Inter-Layer Scheduling Space Exploration for Multi-model Inference on Heterogeneous Chiplets
- Cambricon-LLM: A Chiplet-Based Hybrid Architecture for On-Device Inference of 70B LLM
- The Evolution of Photonic Integrated Circuits and Silicon Photonics
Latest Technical Papers
- Affinity Tailor: Dynamic Locality-Aware Scheduling at Scale
- AMMA: A Multi-Chiplet Memory-Centric Architecture for Low-Latency 1M Context Attention Serving
- Exploring the Efficiency of 3D-Stacked AI Chip Architecture for LLM Inference with Voxel
- Epoxy Composites Reinforced with Long Al₂O₃ Nanowires for Enhanced Thermal Management in Advanced Semiconductor Packaging
- Chipmunq: A Fault-Tolerant Compiler for Chiplet Quantum Architectures