Chiplets: Making the Pieces Work Together
Chiplet architectures promise speed and flexibility, but as systems scale, latency, bandwidth efficiency, and coherence determine real performance.
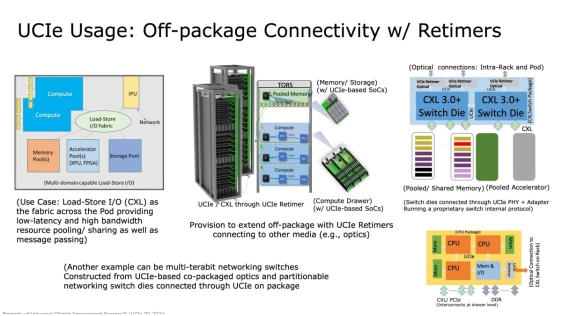 If you ask most engineers what makes chiplets hard, the first answer is usually packaging: interposers vs. organic substrates, thermal paths, bump pitch, signal integrity, yield, and assembly. Those topics matter, but they’re no longer the full story.
If you ask most engineers what makes chiplets hard, the first answer is usually packaging: interposers vs. organic substrates, thermal paths, bump pitch, signal integrity, yield, and assembly. Those topics matter, but they’re no longer the full story.
The deeper shift is architectural. Chiplets turn a “single-die computer” into a distributed system in a package. And as distributed systems have taught us for decades, performance is rarely limited by raw compute alone. It’s limited by communication: the latency of moving data, the availability of bandwidth, and the cost of maintaining a consistent view of memory across many participants (see USENIX’s chiplet network scaling paper).
Packaging Enables Chiplets — Interconnect Determines Whether They Behave Like One System
Chiplets exist because the industry needs new ways to scale beyond the practical limits of monolithic dies — reticle limits, yield constraints, and the desire to mix process nodes and functions. Modern die-to-die standards reflect that motivation explicitly. The UCIe Consortium describes UCIe as a package-level die-to-die interconnect standard that spans physical layer, protocols, and software/compliance, aiming to make multi-vendor chiplet composition feasible (see UCIe Consortium’s specifications).
To read the full article, click here
Related Chiplet
- Integrated voltage regulator (IVR) chiplet
- High-performance connectivity chiplets
- eFPGA Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
Related Blogs
- What are Chiplets and how they Assemble Into the Most Advanced SoCs
- Lowering the Barrier to Chiplets
- Chiplet Summit 2024: Opportunities, Challenges, and the Path Forward for Chiplets
- The Automotive Industry's Next Leap: Why Chiplets Are the Fuel for Innovation
Latest Blogs
- When EMC Shielding Must Bend With the Package
- The Bottleneck Isn’t Compute. It’s Getting the Chip Built!
- How Intel Foundry Packaging Technologies Redefine AI and HPC Scalability Limits at ECTC 2026
- From complexity to simplicity: Scaling and future-proofing chiplets with AMBA®︎ CHI C2C property negotiation
- High-Speed Heterogeneous Integration with Multiphysics Analysis for TSMC SoW-X