HALO: Memory-Centric Heterogeneous Accelerator with 2.5D Integration for Low-Batch LLM Inference
By Shubham Negi and Kaushik Roy
Purdue University, West Lafayette, USA
Abstract
The rapid adoption of Large Language Models (LLMs) has driven a growing demand for efficient inference, particularly in latency-sensitive applications such as chatbots and personalized assistants. Unlike traditional deep neural networks, LLM inference proceeds in two distinct phases: the prefill phase, which processes the full input sequence in parallel, and the decode phase, which generates tokens sequentially. These phases exhibit highly diverse compute and memory requirements, which makes accelerator design particularly challenging. Prior works have primarily been optimized for high-batch inference or evaluated only short input context lengths, leaving the low-batch and long context regime, which is critical for interactive applications, largely underexplored.
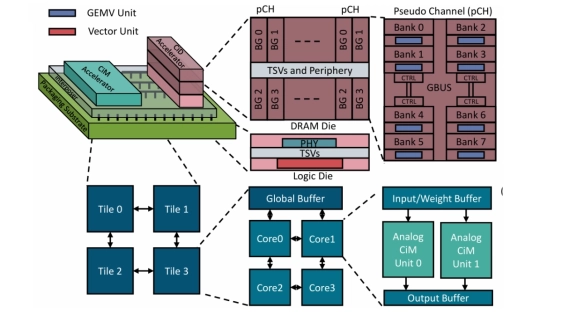
We propose HALO, a heterogeneous memory centric accelerator designed for these unique challenges of prefill and decode phases in low-batch LLM inference. HALO integrates HBM based Compute-in-DRAM (CiD) with an on-chip analog Compute-in-Memory (CiM), co-packaged using 2.5D integration. To further improve the hardware utilization, we introduce a phase-aware mapping strategy that adapts to the distinct demands of the prefill and decode phases. Compute bound operations in the prefill phase are mapped to CiM to exploit its high throughput matrix multiplication capability, while memory-bound operations in the decode phase are executed on CiD to benefit from reduced data movement within DRAM. Additionally, we present an analysis of the performance tradeoffs of LLMs under two architectural extremes: a fully CiD and a fully on-chip analog CiM design to highlight the need for a heterogeneous design. We evaluate HALO on LLaMA-2 7B and Qwen3 8B models. Our experimental results show that LLMs mapped to HALO achieve up to 18x geometric mean speedup over AttAcc, an attention-optimized mapping and 2.5x over CENT, a fully CiD based mapping.
To read the full article, click here
Related Chiplet
- eFPGA Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
- Near-Packaged Optics (NPO) Chiplet Solution
- High Performance Droplet
Related Technical Papers
- A3D-MoE: Acceleration of Large Language Models with Mixture of Experts via 3D Heterogeneous Integration
- Sangam: Chiplet-Based DRAM-PIM Accelerator with CXL Integration for LLM Inferencing
- High-Efficient and Fast-Response Thermal Management by Heterogeneous Integration of Diamond on Interposer-Based 2.5D Chiplets
- Workflows for tackling heterogeneous integration of chiplets for 2.5D/3D semiconductor packaging
Latest Technical Papers
- A Comprehensive Design Framework for Vertical Power Delivery in High-Performance Computing
- SHIFT: Dynamic Compute Relocation Framework for Communication-Aware Chiplet-Based Systems
- Failure Analysis in Transition: An Industry Survey of Challenges, Priorities, and Standardization Needs in Advanced Packaging and Heterogeneous Integration
- 2.5D Root of Trust: Securing the Chiplet Ecosystem
- Plasma Etch Process Optimization for Photonic-Grade Diamond-on-Insulator Substrates and Thickness Evaluation using Colorimetry