Leveraging Chiplet-Locality for Efficient Memory Mapping in Multi-Chip Module GPUs
By Junhyeok Park 1, Sungbin Jang 2, Osang Kwon 2, Yongho Lee 2, Seokin Hong 2
1 Electronics and Telecommunications Research Institute, Daejeon, Republic of Korea
2 Sungkyunkwan University Suwon, Republic of Korea
Abstract
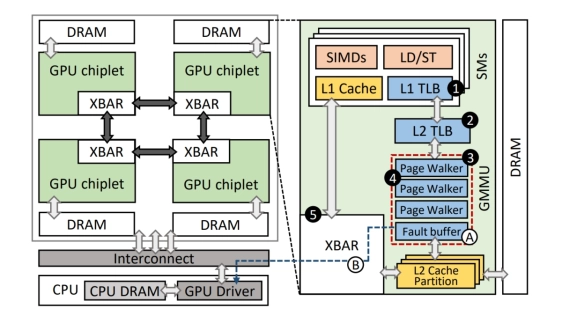
While the multi-chip module (MCM) design allows GPUs to scale compute and memory capabilities through multi-chip integration, it introduces memory system non-uniformity, particularly when a thread accesses resources in remote chiplets. In this work, we investigate how page size in memory mapping affects this non-uniformity. Large pages reduce address translation overhead by covering larger memory regions per TLB entry; however, they enforce coarse-grained data placement, which can lead to data misallocation across chiplets. In contrast, small pages allow for finer-grained placement, increasing the likelihood of mapping data to the chiplet most likely to access it. We observe that application performance is sensitive to page size, with the appropriate configuration depending on workload characteristics.
This paper introduces CLAP which determines the suitable page size—specifically, how much data should be co-located within a single chiplet-for each application. We observe that GPU applications exhibit a distinct memory mapping pattern, in which specific groups of virtually adjacent pages are primarily accessed by the same chiplet with the group size tending to remain consistent - a property referred to as chiplet-locality. Leveraging this insight, CLAP predicts groups of pages exhibit chiplet-locality and preorganizes them to contiguous physical frames within the chiplet most likely to access them. This organization forms regions that behave like large pages, as CLAP enables these page groups to be covered by a single merged TLB entry through deliberate virtualto-physical contiguity. As a result, CLAP delivers the benefits of large pages without compromising chiplet-level memory locality. Our evaluation shows that CLAP improves performance by up to 19.2% compared to previous paging schemes.
To read the full article, click here
Related Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
- Near-Packaged Optics (NPO) Chiplet Solution
- High Performance Droplet
- Interconnect Chiplet
Related Technical Papers
- REX: A Remote Execution Model for Continuos Scalability in Multi-Chiplet-Module GPUs
- DeepOHeat-v1: Efficient Operator Learning for Fast and Trustworthy Thermal Simulation and Optimization in 3D-IC Design
- LEXI: Lossless Exponent Coding for Efficient Inter-Chiplet Communication in Hybrid LLMs
- ELMoE-3D: Leveraging Intrinsic Elasticity of MoE for Hybrid-Bonding-Enabled Self-Speculative Decoding in On-Premises Serving
Latest Technical Papers
- Plasma Etch Process Optimization for Photonic-Grade Diamond-on-Insulator Substrates and Thickness Evaluation using Colorimetry
- CUTh-Solver: GPU-Accelerated Sparse Matrix Solver for High-Resolution Thermal Simulation of 3D ICs
- Making Locality-aware GEMM Compatible with Page-Granularity Placement on Chiplet GPUs
- Advanced semiconductor packaging design via artificial intelligence and machine learning: A review
- DTCO of NOR-Type IGZO FeFETs for 3D Heterogeneous AI Memories: A Read-Centric Perspective