D-Matrix Targets Fast LLM Inference for ‘Real World Scenarios’
By Sally Ward-Foxton, EETimes (January 13, 2025)
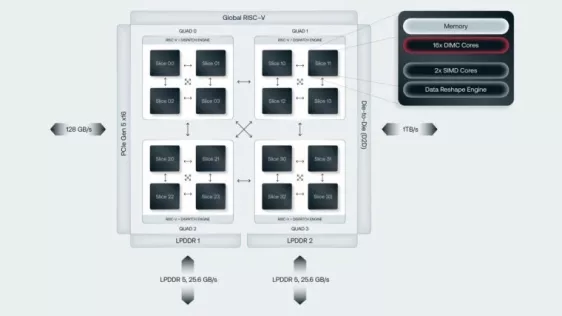
Startup D-Matrix has built a chiplet-based data center AI accelerator optimized for fast, small batch LLM inference in the enterprise, in what the company calls “real-world scenarios.” The company’s novel architecture is based on modified SRAM cells for an all-digital compute-in-memory scheme that the company says is both fast and power efficient.
D-Matrix’s focus is on low-latency batch inference in enterprise data centers. For Llama3-8B, a D-Matrix server (16 four-chiplet chips on eight 600-W cards) can produce 60,000 tokens/second at 1 ms/token latency. For Llama3-70B, a rack of D-Matrix servers (128 four-chiplet chips in a 6-7 kW rack) can produce 30,000 tokens/second at 2 ms/token latency. D-Matrix customers can expect to achieve these figures for batch sizes in the order of 48-64, depending on context length, Sree Ganesan, head of product at D-Matrix, told EE Times.
To read the full article, click here
Related Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
- Near-Packaged Optics (NPO) Chiplet Solution
- High Performance Droplet
- Interconnect Chiplet
Related News
- Breaking the Memory Wall: How d-Matrix Is Redefining AI Inference with Chiplets
- DreamBig World Leading "MARS" Open Chiplet Platform Enables Scaling of Next Generation Large Language Model (LLM), Generative AI, and Automotive Semiconductor Solutions
- DreamBig closes $75M Series B Funding Round, Co-led by Samsung Catalyst Fund and Sutardja Family to Enable AI Inference and Training Solutions to the Masses
- Breaking Through AI Inference Bottlenecks: MSquare Technology’s Cutting-Edge Solutions
Latest News
- Agileo Automation Launches Agil'EDA to Accelerate SEMI EDA Adoption for Semiconductor Equipment OEMs
- AEM and ASE Enter Strategic Partnership to Accelerate AI and HPC Test Innovation
- NLM Photonics Samples Silicon Organic Hybrid PICs Manufactured at GlobalFoundries
- Avalanche Technology and NHanced Semiconductors Leverage Advanced 2.5D Integration to Bring Optimal SWaP and Reliability to Rad-Hard FPGAs
- Open EU Foundry status granted to innovative chiplet facility