Why UCIe is Key to Connectivity for Next-Gen AI Chiplets
By Letizia Giuliano, VP of IP Products, Alphawave Semi
EETimes (February 6, 2025)
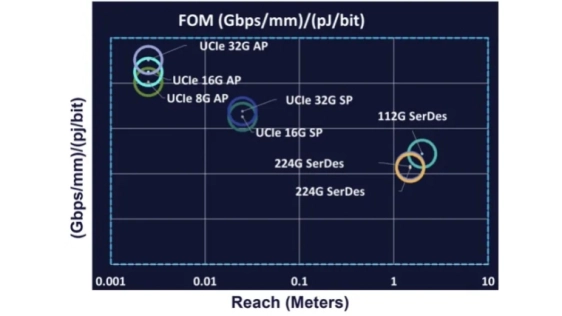
Deploying AI at scale presents enormous challenges, with workloads demanding massive compute power and high-speed communication bandwidth.
Large AI clusters require significant networking infrastructure to handle the data flow between the processors, memory, and storage; without this, the performance of even the most advanced models can be bottlenecked. Data from Meta suggests that approximately 40% of the time that data resides in a data center is wasted, sitting in networking.
In short, connectivity is choking the network, and AI requires dedicated hardware with the maximum possible communication bandwidth.
Deploying AI at scale presents enormous challenges, with workloads demanding massive compute power and high-speed communication bandwidth.
Large AI clusters require significant networking infrastructure to handle the data flow between the processors, memory, and storage; without this, the performance of even the most advanced models can be bottlenecked. Data from Meta suggests that approximately 40% of the time that data resides in a data center is wasted, sitting in networking.
In short, connectivity is choking the network, and AI requires dedicated hardware with the maximum possible communication bandwidth.
The large training workloads of AI create high-bandwidth traffic on the back-end network, and this traffic generally flows in regular patterns and does not require the packet-by-packet handling needed in the front-end network. When things are working properly, they operate with very high levels of activity.
Low latency is critical, as we must have fast access to other resources, and this is enabled by a flat hierarchy. To prevent (expensive) compute being left underutilized, switching also must be non-blocking—it should be noted that the performance of AI networks can be bottlenecked by even one link that has frequent packet losses. Robustness and reliability of the networks are also critical, with the design of the back-end ML network taking this into consideration.
To read the full article, click here
Related Chiplet
- DPIQ Tx PICs
- IMDD Tx PICs
- Near-Packaged Optics (NPO) Chiplet Solution
- High Performance Droplet
- Interconnect Chiplet
Related News
- Marvell to Acquire Celestial AI, Accelerating Scale-up Connectivity for Next-Generation Data Centers
- UMC Licenses imec’s iSiPP300 Technology to Extend Silicon Photonics Capabilities for Next-Generation Connectivity
- Alphawave Semi Taped-Out Industry Leading 64Gbps UCIe™ IP on TSMC 3nm for the IP Ecosystem, Unleashing Next Generation of AI Chiplet Connectivity
- Keysight EDA and Intel Foundry Collaborate on EMIB-T Silicon Bridge Technology for Next-Generation AI and Data Center Solutions
Latest News
- Ayar Labs Closes $500M Series E, Accelerates Volume Production of Co-Packaged Optics
- NanoIC opens access to first-ever fine-pitch RDL and D2W hybrid bonding interconnect PDKs
- GUC Announces Tape-out of UCIe 64G IP on TSMC N3P Technology
- GLS and APES Announce Advanced Semiconductor Packaging Partnership
- Ayar Labs Names Sankara Venkateswaran as Vice President of Engineering