Sangam: Chiplet-Based DRAM-PIM Accelerator with CXL Integration for LLM Inferencing
By Khyati Kiyawat 1, Zhenxing Fan 1, Yasas Seneviratne 1, Morteza Baradaran 1, Akhil Shekar 1, Zihan Xia 2, Mingu Kang 2, and Kevin Skadron 1
University of Virginia 1,
University of California, San Diego 2
Abstract
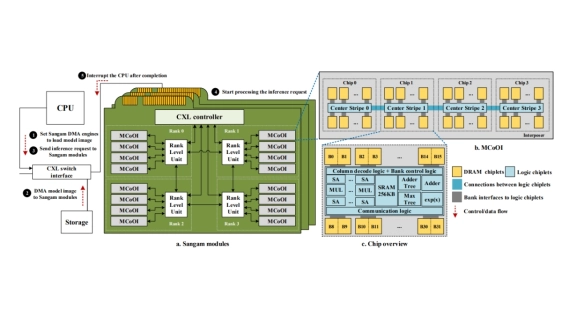
Large Language Models (LLMs) are becoming increasingly data-intensive due to growing model sizes, and they are becoming memory-bound as the context length and, consequently, the key-value (KV) cache size increase. Inference, particularly the decoding phase, is dominated by memorybound GEMV or flat GEMM operations with low operational intensity (OI), making it well-suited for processing-in-memory (PIM) approaches. However, existing in/near-memory solutions face critical limitations such as reduced memory capacity due to the high area cost of integrating processing elements (PEs) within DRAM chips, and limited PE capability due to the constraints of DRAM fabrication technology. This work presents a chiplet-based memory module that addresses these limitations by decoupling logic and memory into chiplets fabricated in heterogeneous technology nodes and connected via an interposer. The logic chiplets sustain high bandwidth access to the DRAM chiplets, which house the memory banks, and enable the integration of advanced processing components such as systolic arrays and SRAM-based buffers to accelerate memory-bound GEMM kernels, capabilities that were not feasible in prior PIM architectures. We propose Sangam, a CXL-attached PIMchiplet based memory module that can either act as a dropin replacement for GPUs or co-executes along side the GPUs. Sangam achieves speedup of 3.93, 4.22, 2.82x speedup in end-toend query latency, 10.3, 9.5, 6.36x greater decoding throughput, and order of magnitude energy savings compared to an H100 GPU for varying input size, output length, and batch size on LLaMA 2-7B, Mistral-7B, and LLaMA 3-70B, respectively.
To read the full article, click here
Related Chiplet
- Interconnect Chiplet
- 12nm EURYTION RFK1 - UCIe SP based Ka-Ku Band Chiplet Transceiver
- Bridglets
- Automotive AI Accelerator
- Direct Chiplet Interface
Related Technical Papers
- HALO: Memory-Centric Heterogeneous Accelerator with 2.5D Integration for Low-Batch LLM Inference
- Chiplet-Gym: Optimizing Chiplet-based AI Accelerator Design with Reinforcement Learning
- Occamy: A 432-Core 28.1 DP-GFLOP/s/W 83% FPU Utilization Dual-Chiplet, Dual-HBM2E RISC-V-based Accelerator for Stencil and Sparse Linear Algebra Computations with 8-to-64-bit Floating-Point Support in 12nm FinFET
- Cambricon-LLM: A Chiplet-Based Hybrid Architecture for On-Device Inference of 70B LLM
Latest Technical Papers
- Probing the Nanoscale Onset of Plasticity in Electroplated Copper for Hybrid Bonding Structures via Multimodal Atomic Force Microscopy
- Recent Progress in Structural Integrity Evaluation of Microelectronic Packaging Using Scanning Acoustic Microscopy (SAM): A Review
- LaMoSys3.5D: Enabling 3.5D-IC-Based Large Language Model Inference Serving Systems via Hardware/Software Co-Design
- 3D-ICE 4.0: Accurate and efficient thermal modeling for 2.5D/3D heterogeneous chiplet systems
- Compass: Mapping Space Exploration for Multi-Chiplet Accelerators Targeting LLM Inference Serving Workloads