Communication Characterization of AI Workloads for Large-scale Multi-chiplet Accelerators
By Mariam Musavi, Emmanuel Irabor, Abhijit Das, Eduard Alarcon, and Sergi Abadal
NaNoNetworking Center in Catalunya (N3Cat), Universitat Politecnica de Catalunya (UPC), Barcelona, Spain
Abstract
Next-generation artificial intelligence (AI) workloads are posing challenges of scalability and robustness in terms of execution time due to their intrinsic evolving data-intensive characteristics. In this paper, we aim to analyse the potential bottlenecks caused due to data movement characteristics of AI workloads on scale-out accelerator architectures composed of multiple chiplets. Our methodology captures the unicast and multicast communication traffic of a set of AI workloads and assesses aspects such as the time spent in such communications and the amount of multicast messages as a function of the number of employed chiplets. Our studies reveal that some AI workloads are potentially vulnerable to the dominant effects of communication, especially multicast traffic, which can become a performance bottleneck and limit their scalability. Workload profiling insights suggest to architect a flexible interconnect solution at chiplet level in order to improve the performance, efficiency and scalability of next-generation AI accelerators.
I. Introduction
Artificial Intelligence (AI) applications have revolutionized multiple fields such as natural language processing, genomics, medical and health systems, graph analytics, and data analytics, and others . However, the impressive feats that AI can achieve are often accompanied by very intense computational demands, which are saturating the boundaries of the traditional computing infrastructures.
To address this, specialised hardware (HW) accelerators are designed that aim at executing specific computational-intensive AI workloads in an efficient manner. GPUs can be considered as hardware accelerators for graphics, that have lately adapted to also better support AI workloads. However, the past decade has seen the emergence and confirmation of specific AI accelerators with workload-specific operations such as, accelerators with tensor or transformer cores as the cornerstone of faster and more efficient AI. Generally speaking, the architecture of AI accelerators is comprised of an off-chip memory, a global shared memory, known as a global buffer, and an array of processing elements (PEs) connected via a Network-on-Chip (NoC) .
As modern AI models are evolving in size and diversity to accommodate multiple applications or to implement input-dependent models such as Graph Neural Networks (GNNs), versatile and high-performance accelerators are required to support their execution. This can be achieved with reconfigurable dataflows in FPGAs , flexible accelerator architectures, or by resorting to less efficient but more general-purpose GPU and CPU architectures .
Another alternative compatible with the scaling and adaptation of AI accelerators is the use of chiplets. Indeed, chiplet technology is a promising enabler that provides a way to scale AI accelerators, by combining together multiple specialized (and potentially heterogeneous) AI accelerator chiplets in a single platform, as illustrated in Figure 1. These chiplets are interconnected among themselves and to memory via on-package links, typically through silicon interposers or organic substrates, in order to create a Network-on-Package (NoP). This has been proposed in multiple works, including SIMBA, WIENNA and others.
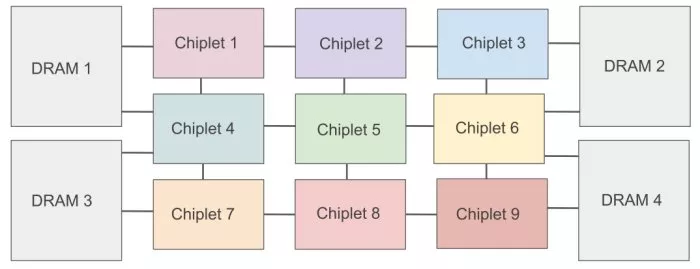
Figure 1:An illustration of multi-chiplet architecture with 3x3 computing chiplets and 4 DRAM chiplets.
It is worth noting that AI accelerator chiplets can spend more than 90 percent of the total system energy on memory-bound tasks, to fetch data, as illustrated in. This is due to not only the limited speed of memory modules, but more importantly, the relatively slow speed of chiplet-to-chiplet data transfers, which can dominate the computation energy due to having to traverse long interconnects. This issue is exacerbated by the need to use multicast communication in many of the dataflows that are used in AI accelerators.
Despite the importance of chiplet-level communication in multi-chip AI accelerators, the communication traffic within such systems has not been explored in depth nor characterized. Traffic characterization and modeling has been well studied in CPU and GPU platforms for a variety of workloads, yet a similar analysis is missing in the proposed context.
The main contribution of this work is the profiling of workload-specific data movements across a set of popular AI workloads in multi-chiplet AI accelerators of increasing size. We augment Gemini to register the communication packets and then parse the resulting traces to analyze their characteristics, e.g. number of messages, destinations per multicast, or number of NoP hops per message.
The rest of the paper is organised as follows. Section II presents the state of the art work in multi-chip AI accelerators and workload characterization. Our methodology is presented in Section III. Section IV presents the results obtained, followed by conclusion and future work presented in Section V.
To read the full article, click here
Related Chiplet
Related Technical Papers
- SCAR: Scheduling Multi-Model AI Workloads on Heterogeneous Multi-Chiplet Module Accelerators
- THERMOS: Thermally-Aware Multi-Objective Scheduling of AI Workloads on Heterogeneous Multi-Chiplet PIM Architectures
- Compass: Mapping Space Exploration for Multi-Chiplet Accelerators Targeting LLM Inference Serving Workloads
- Multi-Objective Hardware-Mapping Co-Optimisation for Multi-DNN Workloads on Chiplet-based Accelerators
Latest Technical Papers
- Link Quality Aware Pathfinding for Chiplet Interconnects
- Effects of Poor Workload Partitioning on System Performance for Chiplet-Based Systems
- Mozart: Modularized and Efficient MoE Training on 3.5D Wafer-Scale Chiplet Architectures
- Network Design for Wafer-Scale Systems with Wafer-on-Wafer Hybrid Bonding
- CarbonPATH: Carbon-aware pathfinding and architecture optimization for chiplet-based AI systems