By Ramin Farjadrad, CEO, Eliyan (February 2024)
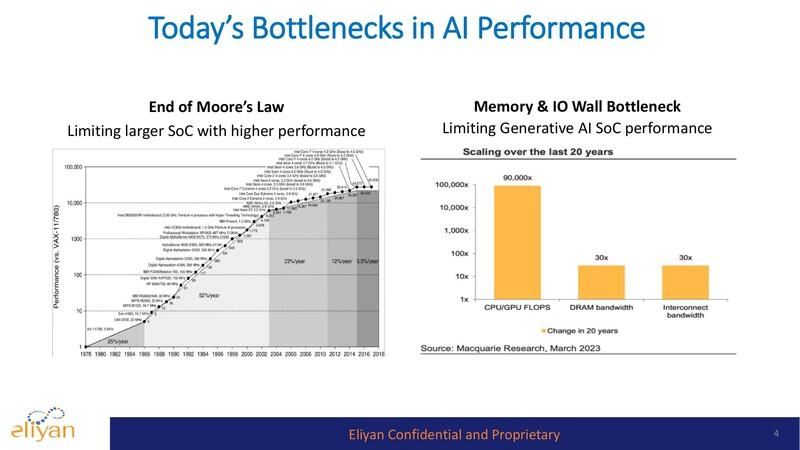
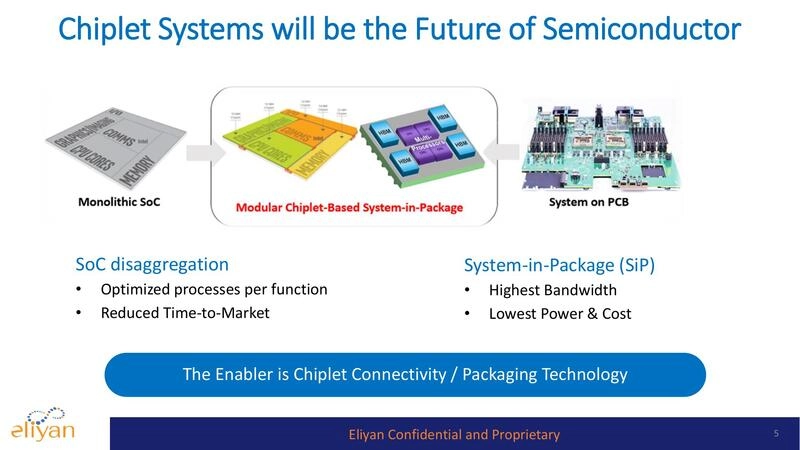
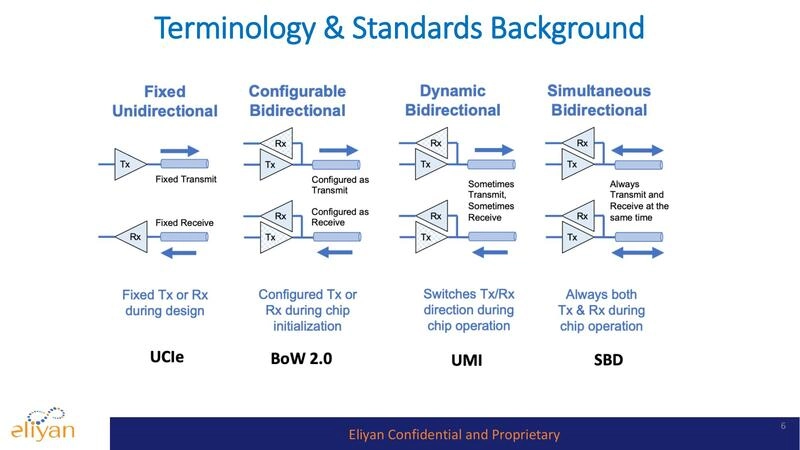
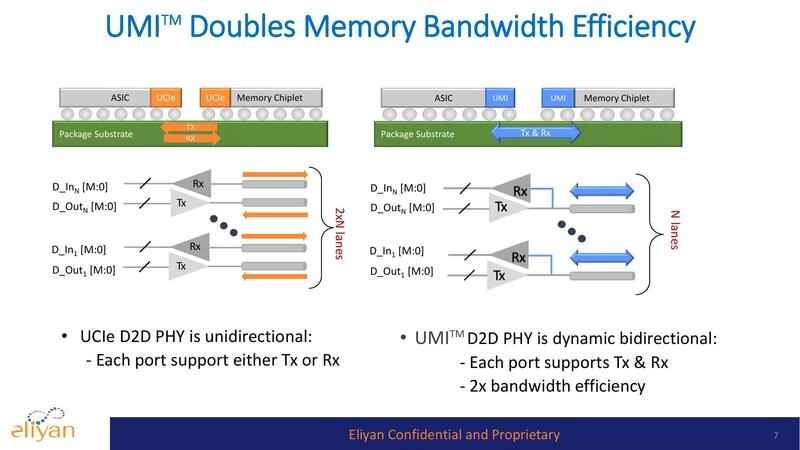
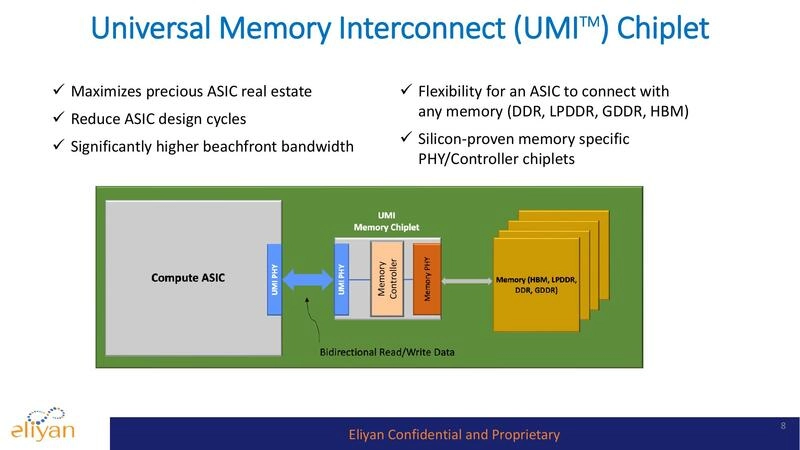
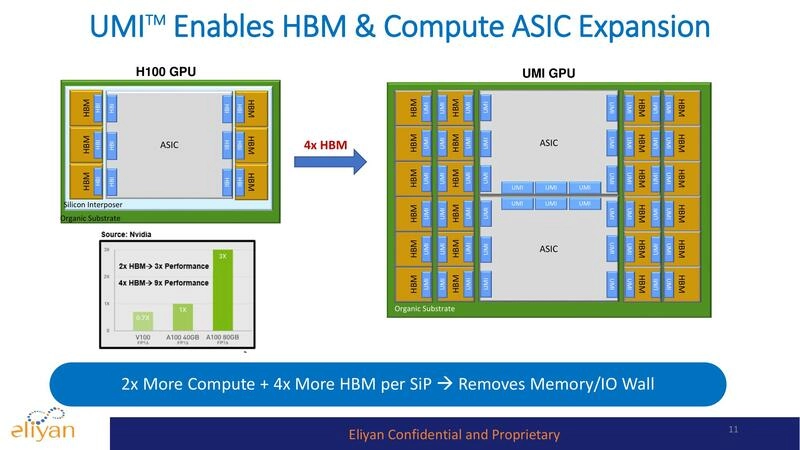
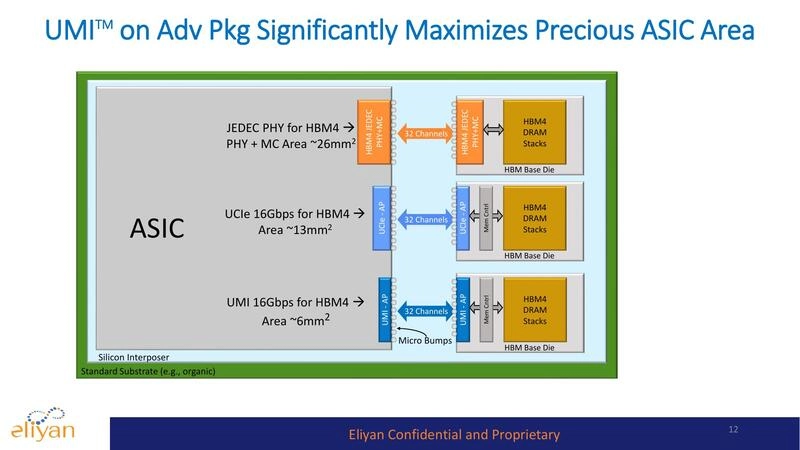
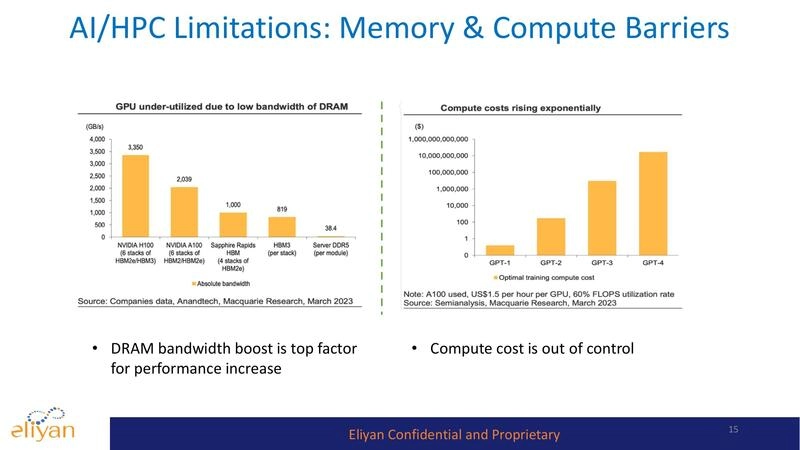
Generative AI, with its huge demand for top performance, requires chiplets containing banks of high-speed memory close to processors. This architecture is essential to breaking through the so-called memory wall (limitations on memory bandwidth and capacity). However, the typical silicon interposer is not large enough to accommodate all the memory that today’s packages could hold. A new approach, called Universal Memory Interface (UMI), provides high-bandwidth D2D connectivity between compute and memory chiplets. It works with standard packaging (no interposer) to implement both high-speed transfers and in-memory computing.